# Swagger limitations for json in/out APIs
At Spike we provide our clients with APIs to access important financial data that is held by South African banks. This article describes our search for a way to create a well structured API on top of an inherently unstructured underlying set of sources.
In the end we used Swagger (opens new window) (largely because our clients wanted this) but we found a number of challenges with this technology. This article highlights the shortcommings we found with Swagger using specific examples from our API.
Of course many of the challenges that we faced come down to our API design - swagger does a great job of ordering and visualising the many ways in which you can define an http endpoint i.e. input method (querystring, webforms, json) as well as outputs (json, xml), stylistic conventions like use of http verbs, and use http status codes. This was all part of the "right way to do things" for REST API's. With the Spike API all functions receive json inputs and produce json outputs - there are no http status codes (everything is a 200 including errors) or verbs (all Spike functions are reads, there's no ability to write, it doesn't seem like this would add anything) or other formats (xml, webforms, ...) to consider. This article is in part a motivation for why we established this json in/out design.
# Overview of the Spike API
First lets summarise the types of data that we provide:
- transactions - a list of those bank transactions that you see in your monthly stateements or in your online banking transaction history. They're useful for loan application processes, tenant vetting etc...
- statements - a pdf from your bank (either a historic monthly statement or some online self-downloadable e-statement). They're also useful for loan application processes but predominantly for compliance purposes.
- account balances - a list of accounts held by a user (account number, account type and balance for each account). This is useful for account verification purposes.
This data is extracted from two sources:
- pdfs - a client provides us with a user's statement and we extract the transactions and account holder info from the pdf;
- web scraping of internet banking sites - a user provides login credentials to their internet banking account and our web scraper[1] logs on as the user and downloads transactions from the banks website.
[1] excuse me our "robotic process automaton"
# Why it's complex to model
I'm sure that you can appreciate how our technology might be complex: implementing pdf parsers for a large number of different bank statement formats (opens new window), as well as trying to keep on top of ever changing bank websites: with fadish access control technologies (let's use a QR code to log in ...), rebranding (it's all about Africanicity, and seeing our money differently ...), front-end technology changes (none (seriously?), jquery, angular, react, ...), security restrictions, site maintenance, performance issues etc...
But that's not the complexity that I want to discuss here. Rather I want to highlight the unique characteristics of our API which are difficult to define in an API spec. This is also a question of API design.
# Multiple schemas are required for both inputs and outputs
It's one thing spec-ing an API which has 1 input per route (/pet?id=10, /orders?from=2019-06-21). It's a different thing entirely trying to describe one that must take multiple different inputs:
// login to ABSA
{
"username": "99121...",
"pin": "12345",
"usernum": "1"
}
// versus login to FNB
{
"username": "ilancopelyn",
"pass": "..."
}
2
3
4
5
6
7
8
9
10
11
Yes we could "design away" the problem by having separate functions /login-absa and /login-fnb - but that's a design decision which might simplify our documentation problem but wouldn't simplify anything for the client: instead of 1 problem ("what inputs do I send to the function?"), now they have 2 problems ("which login function do I use?" as well as "what inputs do I send to the function?")
Remember our challenge here is not to mold our API to the arbitrary constraints of an API specification system but rather to think through what is the easiest interface for our clients to use and understand.
In any event we can't "design away" the requirement to have multiple schemas for our outputs. For example: clients don't know what is in the pdf statement which they send to us - it could be:
// a normal bank statement
{
statement: {/* statement and account holder info */},
transactions: [ { id, date, description, amount, balance} ]
}
// or a credit card statement
{
statement: {/* statement and account holder info */},
breakdown: [
{
category: "PreviousBalance",
name: "Balance brought forward",
total: 9757.98
},
{
category: "Payments",
name: "Payments and credits",
total: 0
},
{
category: "Debits",
name: "Purchases and debits + Interest charged + Default admin + Service fee",
total: 1980.11
}
],
transactions: [
{
id,
category: "PreviousBalance",
transactionDate: "2017-02-07T00:00:00.000Z",
processDate: "2017-02-07T00:00:00.000Z",
description: ["Balance from previous statement"],
amount: 9757.98
},
// ...
]
}
// or a corporate credit card statement with multiple users
[
{ /* credit card statement for user 1 */ },
{ /* credit card statement for user 2 */ },
// etc ...
]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
We could provide a /pdf-identify function, which tells the client which function to call and then separate /pdf-normal, /pdf-credit, and /pdf-credit-multi functions to process the pdf but at double the cost to us (2 requests for every /pdf call where the main processing cost - reading the pdf - must be repeated each time) and adding no benefit to the client.
# Wrapper objects
Of course you want to reduce API complexity for your clients! However simplification is a tradeoff - transforming information throws away some data which might be useful to some clients:
- clients shouldn't have to have a separate path for "FNB just removed the statement download feature from their website... again"[2]
- they probably only want a "success" or "fail" indicator
- hmm... but come to think of it, isn't that something which they'd want to communicate to their users? like a
sorry there's a problem on your banks' site, please try again tomorrowmessage rather thanoops something broke - we dunno what it was
[2] happens about once a month at present, sigh...
If you remove information (i.e. just return { httpStatusCode: 500 }) then there's no way for the client to figure out what to do. However if you provide all information then maybe it's too much detail - maintaining lots of error code specific functionality.
The best strategy that we could come up with to keep both full and summarised data is to use a wrapper object: something that could give the client who just wants to know "did it succeed or did it fail?" what he's looking for as well as something that could give the more inquisitive soul an answer to "ok it broke but can I fix it manually from what you've given me?" or maybe "is there something extra that I need to request from my user?".
All responses from the Spike API are instances of the following wrapper object:
{
requestId,
sessionId,
type,
code,
data
}
2
3
4
5
6
7
- If it's not a session-based request (see below) then that
sessionIdwill be missing. - The
typeis one of:successinterim[3]error
codeis a string which identifies the schema of thedata. And in some cases (likeerror/common/exception) there is nodata- the code is enough for the client to go on.
[3] interim is a success result, however more info is required from the user (e.g. /login isn't complete yet, please enter the one time pin that your bank just SMS'd to you)
# Sessions
The final documentation challenge is to handle session-based requests. All Spike web scrape requests are session-based: you have to /login then possibly /login-step-2[4] before you can ask for /transactions or /statements, and finally you must /close the session. Hence we have to document a set of functions that need to be called in a sequence.
The most useful mechanisms here are probably a flow chart (opens new window) and a sequence diagram (opens new window). API specs tend to be better at describing ins and outs for a single request at a time. Swagger has the ability to include a set of functions (paths) in a single swagger definition but there isn't any way to show the sequence between them. It's more designed for a range of REST functions which all provide you with alternative operations to perform on a given object - i.e. CRUD operations on a single object. For describing a /login process leading to /transaction acquisition it just gets more cluttered to have multiple functions documented in a single swagger definition.
[4] not the actual function name - it's either /login-interim-input or /login-interim-wait because er.. at the time we thought that was more obvious.
# Options for documenting our API
We have a microservices architecture which means that a single request to the Spike API goes through a number of internal services. Our codebase is entirely vanilla node.js - no typescript yet (I'd love to get a chance to change this). So we already had to put a system in place to rationalise all the non-typed instances of data flying about from one service to the next.
The system that we came up with - the "Shape System" (I just made that name up) has the following features:
- uses jsonschema (opens new window) for type definitions (which has an advantage over typescript in that it doesn't get stripped out at runtime - i.e. we can do runtime validation of request inputs)
- has a sanitization system (for obscuring sensitive parts of the inputs during logging)
- the ability to setup a duplex communication channel with a lambda (the awkardly named "backchannel")
- and now the ability to generate swagger definitions (the source of inspiration for this article)
All of these parts can be found in our public api repo (opens new window) - with the exception of the backchannel and our unit tests.
The most popular 3rd party API definition systems appear to be:
GaphQL is becomming increasingly popular and I'd like to experiment more with it. I suspect though that we've covered most of the same ground with our own internal solution (the type system and transformations, mutations, etc...) as well as having some additional features (like sanitization, duplex lambda communication) which would leave little room to be gained from a switch.
Swagger was a common requirement from many of our clients, so in many respects the decision was made for us. At first blush there's a lot to recommend the system: a type definition system (based on jsonschema), a viewer to display the definition, a visual editor, and code generation capabilities (to support multiple language bindings - admittedly I haven't had a chance to play with this yet). However we encountered a number of challenges once starting to describe our API with a swagger spec...
# Swagger shortcommings
We wrote a tool[5] which transforms our internal shape definitions into Swagger OpenAPI 3 (opens new window) compliant specifications. What follows is the list of problems which we encountered whilst using this format to describe our functions.
[5] the imaginatively named swaggerGenerator
# You can't easily describe instances, only schemas
Our errors are all instances of our wrapper object where the .data field is one of 2 shapes:
no-data= the.codealone is sufficient to describe what happened (these errors could be represented by a http status code - but then we would have the challenge of trying to pick the most spec compliant code to represent for example "we can't login because there's a captcha code present")array-of-strings= the error provides some additional data in the form of a list of messages e.g.// input validation error { "requestId": "00000000-0000-4000-a000-000000000001", "code": "error/common/dev/invalid-inputs", "type": 4, "data": ["Request size limit of 6MB exceeded"] }1
2
3
4
5
6
7
We would like to fully document each function API - i.e. list all possible errors which each function can return. To do this requires the ability to list individual instances (error/common/dev/invalid-inputs, error/common/exception, ...) rather than schemas (no-data, and array-of-strings). The issue with constants (below), and the constraints on schema hierarchies, gives me the impression that the spec and tooling were not setup with this purpose in mind.
The workaround which we currently employ is to list each error as a separate schema (with all of the common wrapper fields duplicated) and to use the single enum value trick for constants.
# The tooling (editor & viewer) doesn't support oneOf
In order for the viewer to be useful it has to provide more benefit than you would get by simply opening the .json file in a text editor. There are some nice features when viewing a path with a single schema - like being able to switch between the Example Value and Model. This doesn't work for paths with multiple schemas though (i.e. oneOf).
Single schema (from https://petstore.swagger.io/#/pet/addPet) 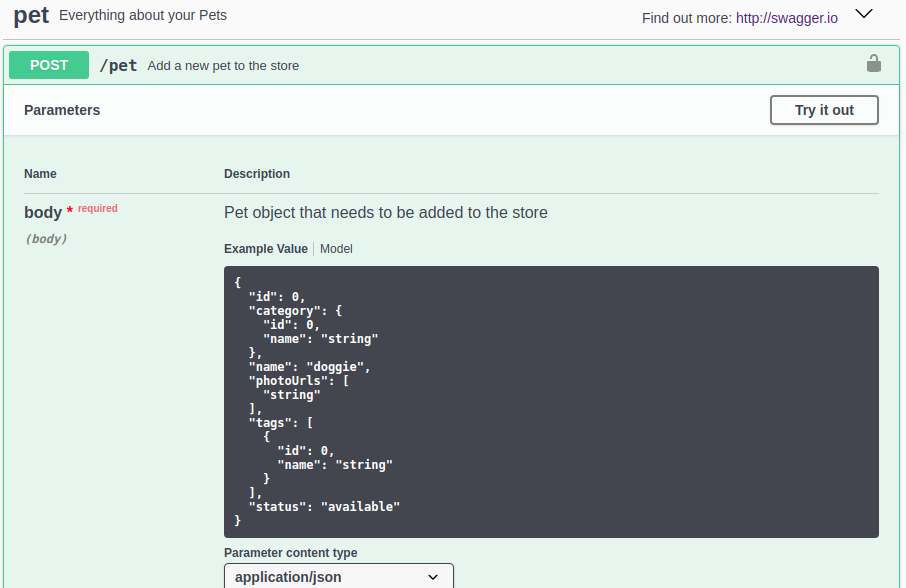
Multi schema outputs (from Swagger Editor (opens new window) with https://api-v6.spikedata.co.za/pdf.yaml loaded) - note the Responses doesn't list any of the schemas: 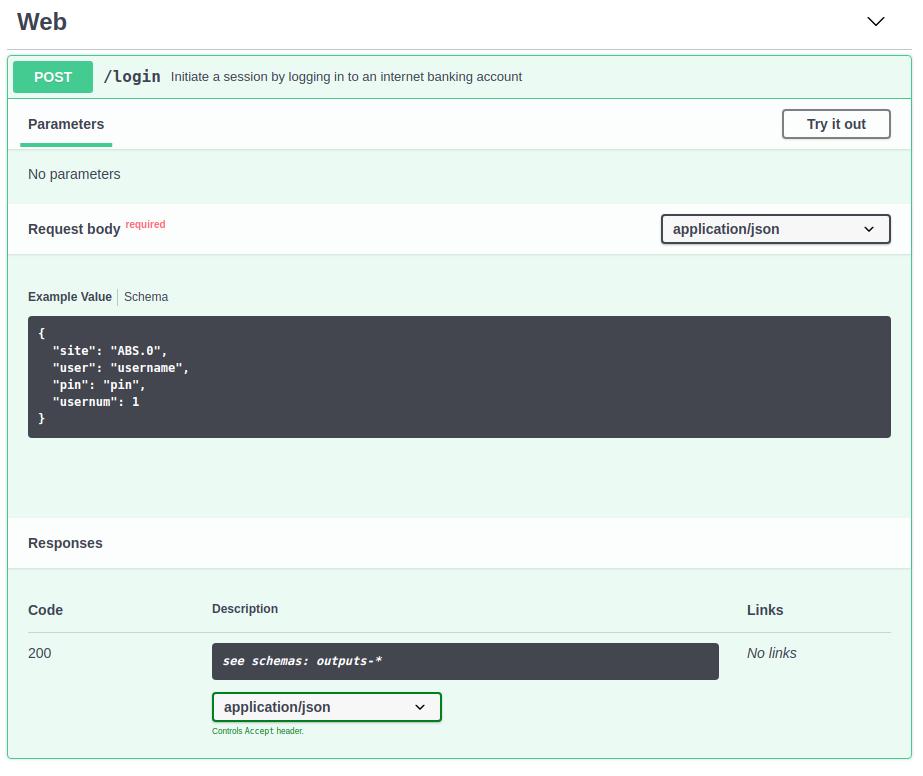
# Non-standard jsonschema spec
There are a number of inconsistencies between the jsonschema used in a Swagger definition and the published jsonschema specs (draft 6 or 7).
# required
The jsonschema required field must be a separate array at the top of schema and cannot appear in field definition i.e.
- this works
"inputs-pdf": {
"type": "object",
"required": [ // here
"file",
"buffer"
],
"properties": {
"file": {
"type": "string"
},
"pass": {
"type": "string"
},
"buffer": {
"type": "string"
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
- not this
"inputs-pdf": {
"type": "object",
"properties": {
"file": {
"type": "string",
"required": true // not here
},
"pass": {
"type": "string"
},
"buffer": {
"type": "string",
"required": true // not here
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# you can't specify a constant value
Constant values are useful for fully documenting all possible responses (i.e. defining instances rather than schemas) - see above. There was some discussion about this here (opens new window). And there is support for constant values (opens new window) in jsonschema (since draft 6). But it's not currently supported in Swagger.
There is a workaround - namely to use single valued enum like so:
{
"type": {
"type": "string",
"enum": ["success"]
}
}
2
3
4
5
6
# you can't use schema hierarchies
You can't have hierarchies under components.schemas. This would be useful for grouping purposes - we have all our errors under one folder, and use subfolders for further categorisations of errors e.g.
- error/common/access/exceeded-max-concurrent-requests.js
- error/common/access/insufficient-credit.js
- error/common/dev/authorization.js
- error/common/dev/invalid-inputs.js
- error/common/exception.js
- error/site/bank-blocked.js
- error/site/captcha.js
In swagger these all have to be flattened under components.schemas:
{
"components": {
"schemas": {
"outputs-error-common-access-exceeded-max-concurrent-requests": { ... },
"outputs-error-common-access-insufficient-credit": { ... },
"outputs-error-common-dev-authorization": { ... },
"outputs-error-common-dev-invalid-inputs": { ... },
"outputs-error-common-exception": { ... },
"outputs-error-fnb-online-banking-legal-documentation": { ... },
"outputs-error-site-bank-blocked": { ... },
"outputs-error-site-captcha": { ... }
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# you can't use your own .ids and .refs
Following on from above you must replace any cross references (.$ref$) with the new non-hierarchical name (#/components/schemas/non-hierarchical-name), and furthermore must delete any .ids that you were using in your jsonschema to link nested schemas.
# you can't use an array of types
If you have a field which can be multiple types you can define this in jsonschema e.g.
// usernum can be an integer or a string
"usernum": {
"type": [
"integer",
"string"
]
}
2
3
4
5
6
7
... but the Swagger viewer/editor doesn't like it 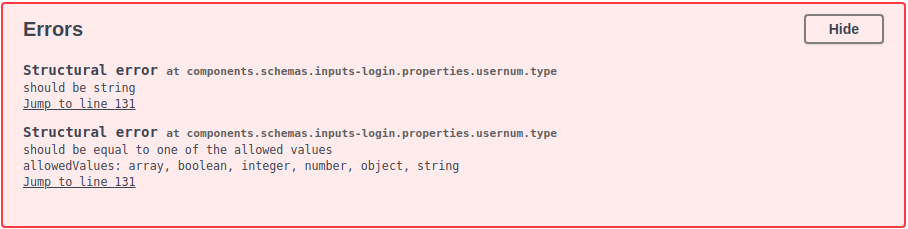
# you can't supply multiple examples
Actually this is incorrect. There is only a singular .example field on a swagger schema no .examples, however it turns out that you can have an array of examples. In fact it looks like .example can actually be anything - even something that doesn't match the schema.
I find the .examples to be very useful for getting a quick understanding of what to send to a function, more so than the type definition. If you have a complicated shape which has optional parts then you might want to show multiple examples in order to document multiple scenarios. For example: we do various types of validation on the transactions that are returned by our /pdf function - e.g. a running total check to see whether there are any breaks = from one row to the next the current balance should equal the current transaction amount + the previous balance. The response is reflects whether breaks were detected or not:
- valid transactions without breaks
{ // .statement omitted transactions: [ { id: 1, date: "2017-09-12T00:00:00.000Z", description: ["Deposit"], amount: 1600.01, balance: 1600.01 } // etc... ], valid: true }1
2
3
4
5
6
7
8
9
10
11
12
13
14 - invalid transactions with breaks
{ // .statement omitted transactions: [ { id: 1, date: "2017-09-12T00:00:00.000Z", description: ["Deposit"], amount: 1600.01, balance: 1600.01 } // etc... ], valid: false, breaks: [ { prev_id: 1, cur_id: 2, amount: -100, diff: -500 }, { prev_id: 2, cur_id: 3, amount: -500, diff: 600 } ] }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
Many of our shapes have only one example - in this case we produce a single swagger .example. When we have 2 or more examples then we generate a Swagger schema with a .example that has multiple nested keys - one for each scenario / use-case e.g.:
- login
"components": { "schemas": { "inputs-login": { "type": "object", "required": [ ... ], "properties": { ... }, "example": { // Multiple examples allows us to show the different inputs // that are required by the 6 different banks that we support "ABS.0": { "site": "ABS.0", "user": "username", "pin": "pin", "usernum": 1 }, "CAP.0": { "site": "CAP.0", "user": "username", "pass": "password" }, "FNB.0": { "site": "FNB.0", "user": "username", "pass": "password" }, "NED.0": { "site": "NED.0", "user": "username", "pass": "password", "pin": "pin" }, "RMB.0": { "site": "RMB.0", "user": "username", "pass": "password" }, "STD.2018-01": { "site": "STD.2018-01", "user": "username", "pass": "password" } } } } } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
# Summary
I wrote this article as something which I could point our clients to when asked why our swagger definition is complicated. It proved to be a valuable exercise in thinking through our API design decisions, ensuring that all scenarios were in fact covered and documented, and describing the API in a format which clients are more readily familiar with.
It brought to light the crux of the problem - which I believe is the mismatch in design paradigms between our "JSON in/out" style design and those of the typical REST based APIS i.e. "status code, http verb, single schema" style designs - for which Swagger seems better suited.
/- Ilan