# OCR statements
Most statements in the SPIKE statement library can be processed by extracting the text directly from the pdf and using positional information (XY co-ordinates) in order to figure out which column a transactional amount falls in to.
However some statements obfuscate the text inside the pdf. One example is the CAPITEC_MERCANTILE_1 format. This format has to processed using Optical Character Recognition (OCR). This is a far more error prone process then the normal statements which we process - the OCR engine may not detect the numbers correctly in an amount or balance. Typical errors include:
- it may join the two together
- skip the cents separator (
101instead of1.01) - or omit the sign (
+100instead of-100)
I've recorded a quick video describing what the problems are with the CAPITEC_MERCANTILE_1 format and demonstrating how to resolve them.
When processing CAPITEC_MERCANTILE_1 statements please be incorporate the following steps into your workflow:
- Pay attention to the
BREAKScolumn in the app - if it isNOT 0then you need to check the csv against the pdf and manually resolve the breaks (i.e. fix the incorrect amount and/or balance values in the .csv) - The video below shows a step-by-step guide on how to resolve the breaks in excel
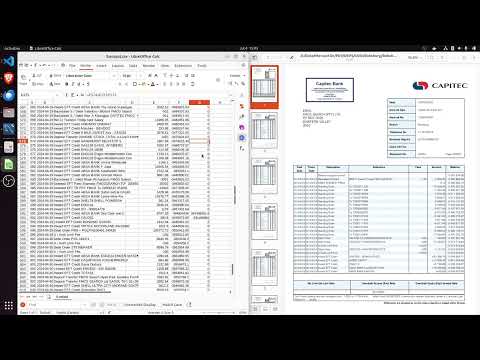
We recoginse that this is not ideal. However it's important to note that this is still a lot quicker than manually trying to process the pdf - in the video it takes less than 4 minutes in order to resolve the problems on an 18 page statement.