# Text vs image pdfs
All original bank statements come in text form. The user has to do something strange (possibly fraudulent) in order to convert the pdf into a picture. You don't want to accept modified statements - only originals.
Only accept original statements
# Text vs picture pdfs
Pdfs contain 2 things - pictures and text. In some cases the entire document is a picture including all of the bank transactions. This frequently occurs when users print a statement and then scan the paper printout with a flat bed scanner.
It can also occur when a user does "print to pdf" on their computer. If you take an original text based pdf statement and "print-to-pdf" you will wind up with 2 pdfs that look visually the same but one will be text the other will be an image.
Spike processes text pdfs, we don't process text from pictures (that's a process called OCR - optical character recognition - which is more complex and costly).
You can check whether a pdf is a text or picture pdf by opening it in a pdf reader (like adobe acrobat) and then double clicking on some text. If you're able to select the text then it's a text pdf and should work in Spike.
# Example
Here's an screenshot showing 2 pdfs that have been opened in Adobe Acrobat:
- an image pdf on the left, and
- a text pdf on the right - notice how you can select text (in blue) here.
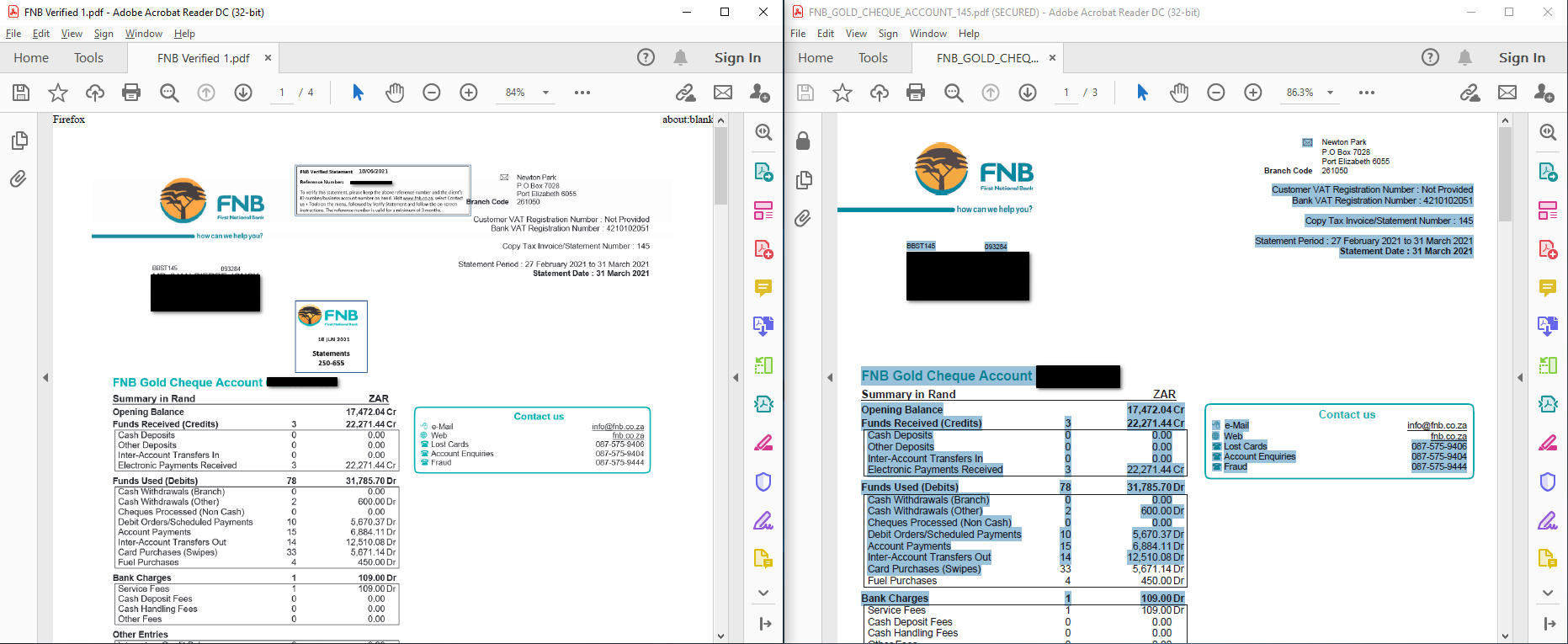
- (note: statements have been redacted in order to obscure personal details)