# Desktop pdf converter
Our desktop pdf converter is useful for clients who have a folder on the computer which contains a number of pdfs that they would like to convert. For example in credit process where teams store pdfs in a shared folder. The desktop converter is a command-line tool which looks through a folder, finds all the statements contained therein, and then converts them in place[1] to a .csv.
NOTE: the desktop pdf converter is currently called spike-pdf-cli.
The tool must be installed on your machine, along with it's dependencies (Node.js), and occasionally updated (if we release fixes or new features).
# Usage
NOTE: @spike/pdf-cli is installed as an executable script called spike-pdf-cli (see package.json:bin (opens new window))
spike-pdf-cli <command>
Commands:
spike-pdf-cli configure Configure the tool with your keys
spike-pdf-cli folder Recurse through a folder and process all .pdfs found
spike-pdf-cli single Process a single .pdf
spike-pdf-cli combine combine .json output from previously processed pdfs into a single .csv
Options:
--version Show version number [boolean]
--help Show help [boolean]
2
3
4
5
6
7
8
9
10
11
# Demo

# How to video
This video shows the desktop converter in action. NOTE: link below opens in YouTube - make sure that you have YouTube > Setting > Quality = 1080p (or at least 720p) in order to see the text in the video.
# Installation
Install Node.js
- Go to https://nodejs.org/en/download/ (opens new window)
- Make sure
LTSis selected, and then pick the downloader for your operating system (most likelyWindows Installer (.msi): 64-bit)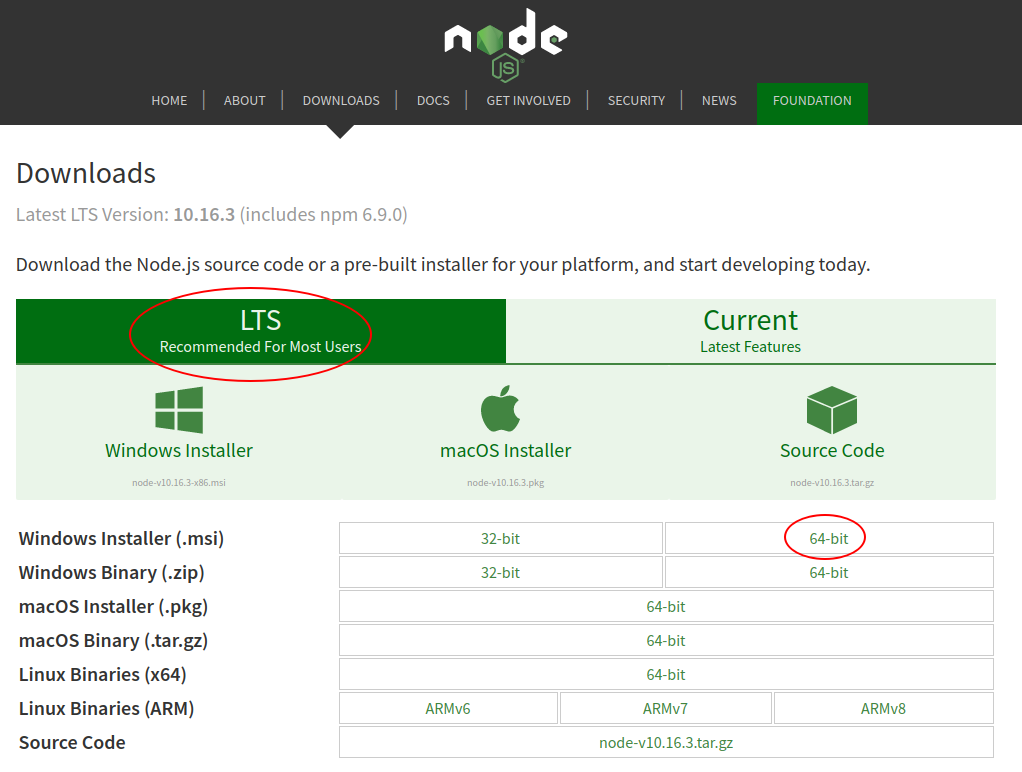
Install[2]
spike-pdf-cliRun a terminal e.g. on windows:
Start > run > cmd.exeThen
npm i -g @spike/pdf-cli # creates global bin = spike-pdf-cli1
Configure
spike-pdf-cliIf you haven't already, create an account on Spike (opens new window)
Now obtain your
tokenfrom settings (opens new window)Run the configuration process:
# run the tool in configure mode spike-pdf-cli configure # example output First run detected, creating config file... Enter you token: # paste your token here wrote config file: C:\Users\ilan\.spike\config.json1
2
3
4
5
6- this will write your keys to the
.spike\config.jsonfile in your home directory
- this will write your keys to the
Setup a
.batfile to runspike-pdf-clithis saves you from having to run
DOSeach time and type in the commandyou can just double click on the
.batfile to runspike-pdf-clicreate a file called
run-spike.batwith the following contents and put it on your desktop:# change `C:\pdfs` to your folder spike-pdf-cli folder --folder C:\pdfs --quiet1
2You can see the full list of commandline options below
# Update
When we release a new version of spike-pdf-cli you will need to run a terminal (e.g. cmd.exe on Windows) and enter the following:
npm update -g @spike/pdf-cli@latest
npm install -g @spike/pdf-cli@latest
2
You can get the version number of your tool like so:
spike-pdf-cli -v
Compare this to the latest released version available here:
# How it works
- You point
spike-pdf-cliat a folder and it will find all the pdfs within the folder (including sub directories) and then uploads each one to the Spike API for processing. - The Spike API extracts transactions and other data (like account holder information) from the statement and returns it to the
spike-pdf-cli. - The
spike-pdf-clicreates a .csv next to the .pdf, containing all the financial transactions from the .pdf. - It writes a summary of all the files processed to date to
folder.csv- in the folder which you indicated above.
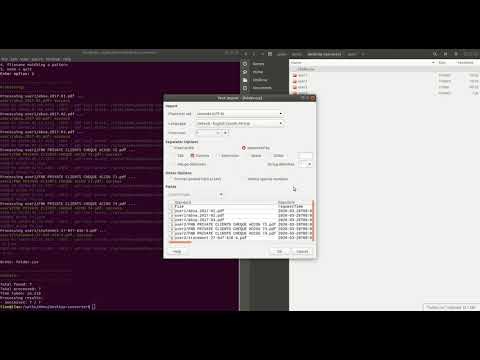
# Use a filter
Note - we use minimatch (opens new window) for filtering. The pattern is applied to the full file path e.g. to filter the following to ABSA only
Pdfs found:
/pdfs/ABSA/1.pdf
/pdfs/ABSA/2.pdf
/pdfs/NED/3.pdf
2
3
4
Use the pattern:
**/ABSA/*"
e.g.
--------------------------------
Which pdfs do you want to process:
--------------------------------
1. all
2. new files only
3. new + prev errors
4. filename matching a pattern
5. none = quit
Enter option: 4
--------------------------------
Enter pattern: **/ABSA/*
2
3
4
5
6
7
8
9
10
11
12
# Commandline arguments
Run the following to get a list of the current arguments:
spike-pdf-cli --help